



A team connects Claude to their eCommerce data warehouse, asks "what was our revenue last week?", and gets a confident number. It looks right. It is not. Revenue existed in three different tables in the warehouse, and Claude picked one without asking. It pulled gross sales instead of the net revenue view that accounts for returns, refunds, and discounts. Nobody catches it until the CFO compares it against the reconciled books.
This is the pattern playing out across mid-market eCommerce right now. Brands get excited about Claude, connect it to their warehouse, and build impressive-looking outputs in a weekend. Six months later, they realize the data underneath is not clean enough for the answers to be trustworthy. The difference between an AI analyst you can trust and one that generates confident nonsense comes down to what sits between the data source and the model: the ingestion layer, the transformation logic, and the business context that tells Claude what your numbers mean in real life.
This guide is a complete Claude data warehouse setup walkthrough, five steps that produce reliable, auditable, business-grade answers when you connect Claude to your eCommerce data warehouse.
Is your data actually Decision-Grade?
9 questions. 3 minutes. Score your Profitability Visibility and Readiness for AI-driven growth.
Start Free Diagnostic
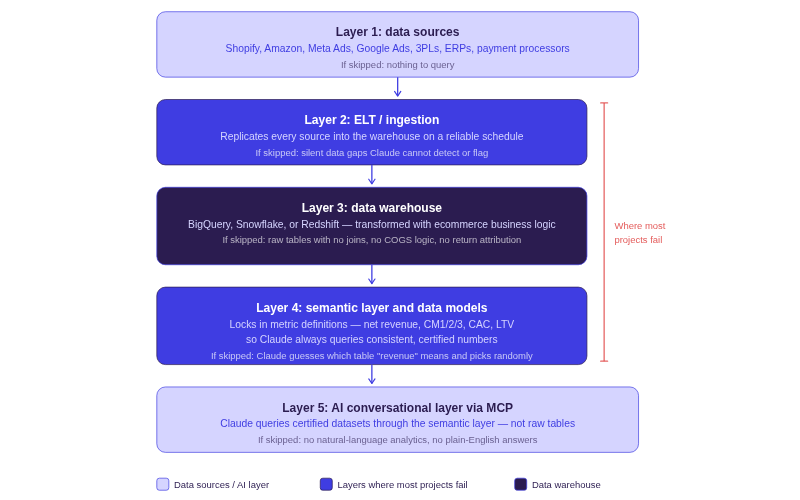
Before You Start: The Architecture at a Glance
Before walking through each step, here is the full stack. Every LLM warehouse connection guide that skips to the MCP configuration misses the layers where most projects eventually fail.
The architecture has five layers:
- Data Sources (Shopify, Amazon, ad platforms, 3PLs, ERPs, payment processors)
- ELT/Ingestion Layer that replicates source data into the warehouse
- Cloud Data Warehouse (BigQuery, Snowflake, or Redshift)
- Semantic Layer and Data Models where business logic, metric definitions, and table relationships are locked in
- AI Conversational Layer via MCP where Claude connects and queries
Layers 2 through 4 are where most of the failures happen. Connecting Claude is the straightforward part. Building an AI ready data warehouse that produces answers you can stand behind in a board meeting, that is the real work.
💡 Real-Time AI Insights: Brands like Momentous have already deployed this architecture with the Saras Analytics platform and moved from days-long reporting cycles to near-real-time AI-powered insights.
👉 Read the full Momentous case study
While this guide uses BigQuery as the primary example (the most common choice for eCommerce brands in the Google ecosystem), the same architecture applies to Snowflake, Redshift, Azure, and others. Saras Pulse supports all of them.
Step 1: Set Up Your Data Warehouse and Ingest Your ECommerce Data
This step gets all your eCommerce data flowing into a single cloud data warehouse on a reliable schedule. If data is not in the warehouse, Claude cannot query it.
Choosing a Warehouse
For most eCommerce brands, BigQuery is the default. It is serverless, scales automatically, and integrates natively with GA4 and the broader Google ecosystem, making eCommerce BigQuery setup one of the fastest paths to a working warehouse. Snowflake suits teams that want multi-cloud flexibility. Redshift fits AWS-heavy stacks.
The warehouse choice matters far less than what goes into it and how it is modeled. A well-structured BigQuery instance will outperform a poorly modeled Snowflake deployment every time.
The Ingestion Layer: Where Complexity Hides
Getting Shopify data to BigQuery is straightforward. So is Google Ads and Meta Ads. Generic ETL tools like Fivetran and Airbyte handle these sources and cover roughly 70% of what a mid-market eCommerce brand needs.
The other 30% is where things break. Amazon Marketing Cloud, Extensiv/3PL Central, Awtomic, custom shipping rate card files, niche returns platforms: scaling omnichannel brands depend on these eCommerce ELT connectors, and generic tools miss them entirely. If you are building an eCommerce data pipeline AI can rely on, those missing sources are not optional. They are the difference between a warehouse Claude can query reliably and one with silent gaps in the data.
One brand spent over $100K building a Fivetran, Snowflake, and Metabase stack. The CFO described the resulting dashboards as "90% wrong." The connectors worked fine for Shopify and Google Ads. Everything else required months of custom scripts and manual CSV exports.
Saras Daton was built specifically for this gap: a purpose-built eCommerce ELT platform with 200+ eCommerce data connectors covering the long-tail sources generic tools leave behind, with replication speeds up to every 15 minutes.
Step 2: Transform and Model Your Data
Raw data in a warehouse is not queryable data. It is disconnected tables with inconsistent naming, duplicated records, and zero business logic. Think of it like buying vegetables at the market: the raw ingredients are necessary, but they are useless until you chop, prep, and organize them into a meal. This step turns raw tables into structured, business-logic-enriched datasets that represent how your company operates. It is also the step where the DIY approach typically takes two to four months of a data engineer's time.
What ECommerce Transformation Actually Looks Like
Most teams underestimate what this step requires. Here is what transformation means for eCommerce, specifically:
- Return attribution: Joining Shopify orders with returns data so a refund processed 45 days later restates the original order's margin correctly.
- Kit unbundling: Breaking subscription bundles into component SKUs so COGS, pick-and-pack fees, and shipping weight are allocated per product instead of treated as a single blended line item.
- Date-effective COGS: Applying Q1 manufacturing costs to Q1 orders and Q4 costs to Q4 orders, rather than a single static number that destroys historical accuracy.
- 3PL invoice matching: Joining fulfillment invoices at the order-line level so shipping costs reflect actual dimensional weight and carrier zone, not blended monthly averages.
Consider a subscription brand selling a "Morning Essentials" box with three products. Without kit unbundling, COGS shows as one blended number. When they swap a component for a cheaper alternative, the margin improvement is invisible because the bundle is still treated as a single line. Their contribution margin looks flat when it improved by 8 points on that SKU.
As Ben Yahalom, CEO of True Classic, put it: "Before Saras, our P&L was built on estimates and pieced together from various tools." That gap between estimates and actuals is exactly what transformation eliminates.
DIY vs. Managed Transformation
Building this yourself means writing SQL transformation models in dbt on top of raw warehouse tables. It works, but it is slow to build, expensive to maintain, and creates key-person risk if the engineer who wrote the models leaves.
Saras Pulse provides a managed eCommerce data warehouse with pre-built models where the transformation logic for common eCommerce patterns, return attribution, kit unbundling, COGS management, multi-channel reconciliation, is already built. Brands customize to their specific business rules rather than starting from scratch.
Step 3: Add a Business Context Layer
The semantic layer eCommerce AI tools need to produce consistent, trustworthy results is essentially a business context layer. It sits on top of your modeled data and locks in what every metric means. Without it, Claude has to infer what "revenue" means from column names, and it will infer differently depending on how you phrase the question.
With a business context layer in place, "net revenue" always means gross revenue minus returns, minus discounts, minus tax, regardless of whether Claude answers the question, a Looker dashboard displays it, or a Google Sheet formula pulls it.
What the Business Context Layer Contains
For eCommerce brands, this layer includes: certified metric definitions (net revenue, contribution margin at CM1/CM2/CM3 levels, ROAS, LTV, CAC), defined relationships between tables (orders to returns, orders to fulfillment costs, orders to ad spend attribution), thresholds and business rules (what does "last week" mean for your business, when does your financial week start, what attribution window do you default to), and data lineage so every number is traceable back to the source record.
This is the layer that separates Claude giving you an answer from Claude giving you the right answer. Without it, the same question asked two different ways can produce two different numbers.
As Lauren Festante, SVP Finance at Momentous, noted: "Saras helped strengthen this foundation by improving the consistency and visibility of our product and margin data."
Building vs. Buying the Semantic Layer
The DIY path means implementing a tool like dbt's semantic layer, LookML, or Cube.dev, then manually defining every metric, dimension, and relationship. For a mid-market brand with 5 to 10 data sources, this is a four-to-eight-week project for an experienced analytics engineer, with ongoing maintenance as the business evolves.
Saras Pulse includes a semantic layer purpose-built for LLMs and BI tools as part of its AI-ready data foundation. It ships with pre-built eCommerce metric definitions, supports custom business logic, and pushes certified data into any downstream tool, including Claude via iQ MCP.
Step 4: Connect Claude via MCP
MCP (Model Context Protocol) is an open standard that lets AI tools like Claude securely connect to external data sources. The simplest way to think about it: MCP sits between your database and the LLM. It handles authentication, data access, and query execution so you can complete a Claude MCP configuration without building a custom API.
For implementation-minded teams, here is what matters: this is the shortest step in the entire LLM warehouse connection guide. The Claude connection is straightforward. The data preparation underneath it is the real work.
Raw Tables vs. Semantic Layer: The Critical Distinction
What Claude queries through MCP determines the quality of every answer it produces. If MCP connects Claude to raw, unmodeled tables, you get wrong answers delivered with confidence. If MCP connects Claude through the semantic layer with certified definitions, you get trustworthy, auditable analytics. Every step before this one exists to make this distinction possible.
Important: MCP is the transport layer, not the intelligence layer. Connecting Claude to raw tables through MCP does not improve the answers. It delivers unreliable answers faster.
For DIY teams, building an MCP server using the open-source specification is feasible. But you still need a semantic layer underneath for the connection to produce results anyone can trust. Building the MCP server is a weekend project. Building the data foundation it connects to is the multi-month work.
Saras iQ MCP lets you plug Claude into your warehouse via MCP through the semantic layer, not raw tables. Every query routes through certified datasets with locked-in metric definitions and proper table joins. For a Claude BigQuery integration backed by governed data, this is the fastest path to production.
Step 5: Validate and Go Live
The most dangerous failure mode is a plausible wrong answer. Claude will never say "I don't know." It will always generate a response. If the data foundation has a gap, a missing join, an incorrect COGS mapping, an unhandled return type, the answer will look precise and professional but be wrong.
At one company, data accuracy was questioned during an all-hands meeting with investors present. The CFO's demand was straightforward: "All the different business partners need to believe in the accuracy and timeliness of the reporting." Validation is the step that earns that trust.
Claude Data Warehouse Setup: Validation Checklist
- Pick 5-10 questions with known answers Choose questions your finance and ops teams can already verify manually before asking Claude (e.g., Total net revenue last month, Contribution margin by channel, Top 10 SKUs by profit).
- Ask Claude each question via MCP Run every question through the configured MCP ecommerce data warehouse connection exactly as a real user would ask it.
- Compare against manually reconciled numbers Put Claude's answers side by side with the numbers your team has already calculated. Flag any gap, however small.
- Trace the SQL for any discrepancy For each mismatch, inspect the SQL Claude generated and identify the root cause (Data model gap, Semantic definition mismatch, Missing source).
- Fix the data model, not the prompt Correct the root cause in the data model or semantic layer. Prompt-engineering Claude into the right answer is not a fix it breaks the next question.
Watch for this signal: If Claude's answer is within 2% of your reconciled number, the data model is working. If it is off by more than 5%, the issue is almost always in the transformation or semantic layer. Better prompts will not fix bad data.
Saras iQ, the AI eCommerce analyst built on this stack, surfaces the execution steps behind every response: the SQL that was run, the tables queried, and the business logic applied. That traceability makes validation dramatically faster than debugging a black-box LLM output.
Build vs. Buy: An Honest Comparison
As one AI strategist working with mid-market eCommerce brands put it: "You're going to do all this AI enablement. And in six months, you're going to realize the data isn't good enough to do this. I would love to save you those six months."
Here is an honest comparison of the two approaches to a Claude eCommerce data warehouse setup:
The honest nuance: the DIY path gives maximum control and is the right choice for brands with a strong in-house data engineering team and highly custom requirements. For most eCommerce brands between $20M and $200M in revenue, the managed approach delivers better outcomes faster because the hard eCommerce-specific patterns (kit unbundling, return attribution, date-effective COGS, multi-channel reconciliation) have already been solved.
💡 Unify Your Data Ecosystem: True Classic unified 40+ disconnected tools into one data ecosystem and saved over 1,000 hours.
👉 Read the full True Classic case study
For brands that want a fully hands-on partner, Saras also offers eCommerce data engineering services with a dedicated team to build and manage the entire stack.
Conclusion
Having data in a warehouse is step one, not the end goal. The real value comes when that data is ingested from every source (not just the easy ones), transformed with business logic that matches how your company actually operates, certified through a semantic layer that eliminates conflicting definitions, and connected to Claude through MCP so any team member can ask a question in plain English and trust the answer.
Talk to the data consultants at Saras Analytics to see how the full stack, Daton, Pulse, and iQ, can get you from raw data to trusted AI-powered answers in a fraction of the time it would take to build in-house.

.svg)
.png)
%201%20(1).svg)


















.png)





.png)










.png)











.png)









.png)





.png)










.webp)


.avif)















.avif)

.avif)
.avif)
.avif)
.avif)



