



The most dangerous thing about connecting Claude to BigQuery is how easy it is. You can set up a Model Context Protocol (MCP) connection in an afternoon, point Claude at your eCommerce data warehouse, and start asking questions in plain English. Claude will oblige. It will write SQL, query your tables, and return precise-looking numbers. The problem is those numbers will be wrong.
What makes this hallucination more insidious than AI fabricating facts from thin air is that Claude is running real queries against real data. The output looks credible because the underlying tables are real. But without a semantic layer that tells Claude what your data means, every answer is a confident guess dressed in SQL. The gap between "connected" and "trustworthy" is entirely a data engineering problem, and closing it requires a semantic layer that gives Claude the business context raw tables can never provide.
This article walks through a practical three-step framework for making that connection trustworthy: centralize, certify, converse.
Is your data actually Decision-Grade?
9 questions. 3 minutes. Score your Profitability Visibility and Readiness for AI-driven growth.
Start Free Diagnostic
Why Raw BigQuery Tables Make Claude Hallucinate
When you point Claude at a raw Shopify data dump in BigQuery, it sees column names like total_price, line_item_price, and total_discounts. These labels are ambiguous even to a human analyst who's new to your schema. For Claude, they're a guessing game. Does total_price mean gross revenue? Net revenue? Revenue after discounts but before tax? Claude picks an interpretation and commits to it, with no way to know it chose wrong.
Here's what that looks like:
Ask Claude, "What was my contribution margin last month?" against raw tables. Claude will likely sum up the total_price column, which includes tax and discounts it shouldn't count. It will miss the returns table entirely because there's no defined relationship telling it that returns reduce net revenue. It might pull COGS from a column that holds wholesale list prices. Fulfillment costs sitting in a separate 3PL dataset won't even enter the calculation. The final number looks precise: "42.3%." It's backed by SQL you can read. And it's completely wrong.
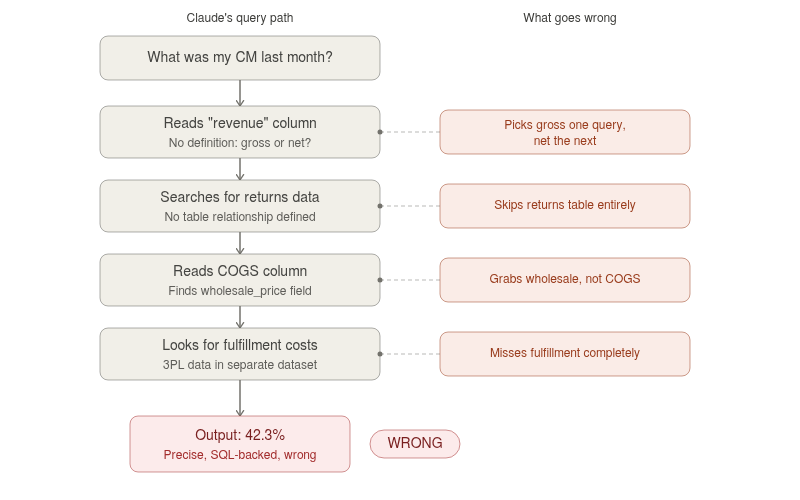
The root cause behind AI hallucination: LLMs interpret column names literally. They have no concept of "net revenue means gross revenue minus returns minus discounts minus tax." Without explicit definitions that map your schema to your business logic, every contribution margin analysis becomes a confident hallucination. And the problem compounds with every additional data source.
A scaling eCommerce brand has Shopify orders, Amazon Seller Central reports, 3PL shipping invoices, and ERP data all sitting in BigQuery — and Claude has to piece together relationships across datasets that were never designed to work together. According to a 2026 industry analysis, the average online retailer now runs between 15 and 30 different software applications. Each one writes data in its own schema, its own naming conventions, and its own update cadence. Claude has to make sense of all of it with zero business context.
Watch for this signal: If Claude returns a specific-looking number like "42.3% contribution margin" without first asking which cost components to include, it's guessing. A system you can trust asks clarifying questions — "Do you mean CM including or excluding ad spend?" — before returning a number.
What Does "AI-Ready" Actually Mean for eCommerce Data?
"AI-ready" is a specific technical state, not a marketing label. It means three building blocks are in place between your raw data and any AI tool that queries it.
The progression maps to a data maturity journey that most mid-market eCommerce brands are somewhere in the middle of. Getting data into a warehouse is step one. Cleaning and modeling it is step two. The semantic layer — where definitions are certified and governed — is where most brands stall. It's also the step that makes the difference between an AI tool that guesses and one that knows.
Momentous, a DTC supplements brand, went through this exact progression. They replaced fragmented reporting across disconnected tools with an AI-ready data foundation that delivered near-real-time insights. The breakthrough came from building the certified data layer underneath, which then made the AI useful. Read the full case study →
An LLM eCommerce data warehouse setup that skips the semantic layer looks functional on the surface. Claude connects, queries run, numbers come back. But those numbers won't match what your finance team produces, and the moment a CFO spots the discrepancy, trust in the entire system collapses.
The Role of MCP in Connecting Claude to Your Data
MCP (Model Context Protocol) is an open standard that lets AI tools like Claude securely connect to external data sources without requiring a custom API build for each one. Think of it as a standardized plug: Claude on one side, your BigQuery warehouse on the other, MCP handling the secure handshake in between.
The protocol does its job well. It moves data between Claude and BigQuery efficiently and securely. The distinction that matters, though, is that MCP is the pipe — not the water quality filter. If what flows through that pipe is messy eCommerce data with ambiguous column names, no defined joins between tables, and no business logic applied, Claude's outputs will be equally messy.
Important: MCP + clean, semantically modeled data = trusted answers. MCP + raw, unmodeled data = bad answers delivered faster, with better formatting.
This is why a Claude BigQuery integration alone doesn't solve the trust problem. The integration works. The data underneath it doesn't. Saras iQ MCP is built specifically for this gap. Instead of connecting Claude to raw BigQuery tables, it connects Claude to semantically modeled eCommerce datasets where "net revenue," "contribution margin," and "fulfillment cost per order" already have locked-in definitions.
Claude queries through the iQ MCP server and receives answers grounded in certified business logic, not raw column interpretations. The difference is between Claude guessing what total_price means and Claude knowing exactly what "contribution margin after returns and fulfillment" means — because the semantic layer spells it out.
Step 1: Centralize and Ingest Your eCommerce Data
Before Claude can answer a single question reliably, every data source needs to land in BigQuery on schedule and without gaps. That means Shopify orders, Amazon Seller Central reports, Meta and Google ad spend, 3PL shipping invoices, ERP data from NetSuite or QuickBooks, payment processor records from Stripe, returns data from Loop or Returnly — all in one warehouse, deduplicated and consistently structured.
Most general-purpose ETL platforms cover roughly 70% of what a scaling eCommerce brand needs. They handle Shopify and Google Ads fine. The gap is the long tail: Amazon Marketing Cloud, subscription platforms like Awtomic or Recharge, 3PL systems like Extensiv, or custom shipping rate card data. That missing 30% is where teams end up building manual export scripts, downloading CSV files weekly, and creating exactly the kind of fragile patchwork that makes BigQuery hallucinations inevitable.
True Classic faced this problem across more than 40 disconnected tools. Centralizing that data into one ecosystem saved over 1,000 hours of manual work and eliminated the reconciliation headaches that came with it. Read the full case study →
Saras Daton, a purpose-built eCommerce ELT platform, provides 200+ eCommerce data connectors that cover both standard platforms and the long-tail sources generic ETL tools miss. Incremental extraction keeps loads efficient, schema mapping is pre-configured for commerce data, and replication speeds run as fast as every 15 minutes. The point is making sure all your MCP eCommerce data is in BigQuery before Claude ever tries to query it.
Step 2: Model and Certify Your Data with a Semantic Layer
Raw data in a warehouse is like raw ingredients on a counter. The value comes from how you prepare them. In eCommerce data terms, that preparation includes joining Shopify orders with 3PL invoices so fulfillment costs are allocated at the order-line level, not blended across the month. It includes unbundling kits and subscription boxes into component SKUs so COGS, pick-and-pack fees, and shipping weights split accurately. Date-effective COGS matter too: Q1 manufacturing prices should hit Q1 orders, not a single static average carried across the year.
Consider a brand selling bundles of three products. In Shopify, that bundle is one line item. In the 3PL system, it's three separate picks. In the COGS table, each component has a different cost. Without modeling that breaks the bundle into its parts, Claude sees one product at one price point and has no way to calculate accurate unit economics. Every margin question about that bundle will be wrong.
The semantic layer for LLMs sits on top of these modeled datasets. It's the governance layer that locks in what each metric means. "Net revenue" always equals gross revenue minus returns, minus discounts, minus tax — no matter who asks or which tool queries it. Your CFO running a Looker report sees the same number that Claude returns. No conflicting definitions. No "which number is right?" meetings.
As Ben Yahalom, CEO of True Classic, described the pre-foundation state: "Before Saras, our P&L was built on estimates and pieced together from various tools." That's the reality for most brands querying raw BigQuery data through Claude. The estimates just get delivered faster.
Saras Pulse, a managed eCommerce data warehouse with pre-built models, provides a pre-modelled eCommerce data warehouse with a semantic layer built specifically for LLMs and BI tools. Business logic unique to your brand — whether that's custom shipping allocation rules, specific bundle unbundling structures, or how you handle retroactive carrier surcharges — gets codified in the semantic layer rather than assumed. The result is that when you connect an LLM to this data warehouse, the definitions are already there, eliminating BigQuery hallucinations from the start.
Step 3: Add a Conversational AI Layer
Once your data is centralized, modeled, and semantically certified, connecting Claude on top becomes a matter of plugging in rather than a multi-month engineering project. The hard work lives in the data foundation; the conversational layer is the payoff.
Saras iQ, the eCommerce AI analyst built on top of this foundation, lets teams ask business questions in plain English and receive answers with visualizations, backed by traceable SQL. Every response shows the execution steps behind it: what query was run, which tables were hit, how the metric was calculated.
When a question is ambiguous, iQ asks for clarification ("Do you mean contribution margin including or excluding ad spend?") rather than guessing and hoping. Insights can be shared to Slack, email, or Teams in one click.
How Saras iQ Fixes the Problem
The core difference comes down to what sits between Claude and your data. When Claude queries raw BigQuery tables, it interprets column names, guesses at joins, and defines metrics on the fly. When Claude connects through iQ's governed context layer, it inherits your business logic, your metric definitions, and your calculation rules before it writes a single line of SQL. A 2026 benchmark across 37 LLMs found hallucination rates between 15% and 52% on structured analysis tasks. That range narrows dramatically when the model isn't left to interpret raw data on its own.
What Changes When Claude Stops Guessing
Take the question "What's my contribution margin by channel this quarter?" and run it two ways.
Against raw BigQuery data, Claude guesses at which revenue column to sum. It misses returns because the returns table isn't joined to orders. It ignores marketplace fees because they sit in a separate dataset Claude doesn't know about. It skips 3PL fulfillment costs entirely. The number comes back looking clean: a channel-level breakdown, formatted in a table, backed by SQL. It's off by 8 to 12 percentage points.
Through a semantically modeled warehouse, the same question returns an auditable, channel-level breakdown that matches what your finance team sees. Same metric definitions, same cost allocations, same joins. The difference is that every step is traceable. You can open the SQL, see which tables were queried, and verify the logic. There's nothing to take on faith.
The business impact goes beyond accuracy. Decisions that used to wait for the monthly close happen in minutes. Teams stop exporting data into spreadsheets for "manual validation." Monday meetings stop being debates about whose number is right. As Jordan Narducci, Head of eCommerce at Momentous, put it: "The ability to monitor the impact of various initiatives on retention in real-time through their cohort dashboards was an absolute game changer."
This operates at enterprise scale. The platform supporting these answers runs at 99.9%+ availability, connects to 5,000+ APIs, and processes over 10 million jobs per day. This is production infrastructure that brands like HexClad — 77 data integrations, five currencies, 99.5% data accuracy — already run their operations on.
Summary
Connecting Claude to BigQuery takes five minutes. Making that connection trustworthy takes an AI-ready data foundation. The three steps are clear: centralize all eCommerce data into BigQuery with reliable, purpose-built connectors. Transform, model, and certify that data with a semantic layer that locks in every metric definition. Then add a conversational AI layer that queries the semantic layer — not raw tables — so every answer is grounded, traceable, and auditable.
The brands that get this right stop debating numbers and start acting on them.
Talk to the data consultants at Saras Analytics about building your AI-ready data foundation for eCommerce.

.png)
.svg)
%201%20(1).svg)


















.png)





.png)










.png)











.png)









.png)





.png)










.webp)


.avif)















.avif)

.avif)
.avif)
.avif)
.avif)



